過去のWebサイトを丸ごとローカルへ復元するWarrick
InternetArchiveには過去のWebのアーカイブが保存されている。私が90年代に運営していたaccess.or.jpというWebサイトを見たければ、
http://web.archive.org/web/*/http://www.access.or.jp
から日付選択でその日の姿のWebを表示させることができる。
とても便利なアーカイブサービスだが、バックアップされたサイト全体をダウンロードするのは面倒である。Warrickを使うと一行の指示でその作業を自動で行ってくれる。
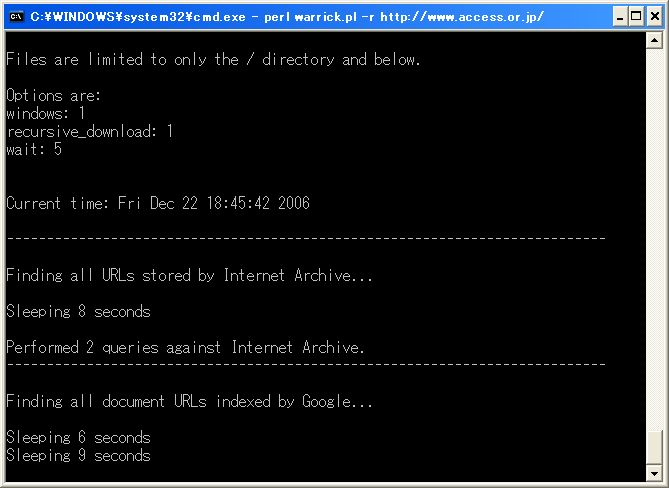
動作にはPerlが必要だ。コマンドラインから、たとえば、
という命令を出すと、InternetArchive、Google、Yahoo!、MSNのキャッシュにアクセスして復元に必要なファイルを探してくれる。-rはリンクをたどって再帰的にサイト全体をダウンロードするオプション。
・サーバのクラッシュで失われた自分のサイトのデータを取り戻す
・事件や事故で消されたサイトを復元してみる
といった目的で使えそうである。
